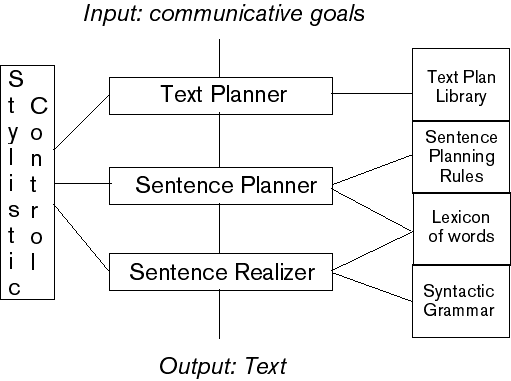
Figure 1 Architecture of idealized complete text generation system (without feedback between modules).
Automated natural language generation (NLG), currently about 25 years old, investigates how to build computer programs to produce high-quality text from computer-internal representations of information. Generally, NLG does not include research on the automatic production of speech, whether from text or from a more abstract input (see SPEECH SYNTHESIS). Also, with few exceptions, research has steadily moved away from modeling how people produce language to developing methods by which computers can be made to do so robustly.
The information provided to a language generator is produced by some other system (the "host" program), which may be an expert system, database access system, MACHINE TRANSLATION engine, and so on. The outputs of various host systems can differ quite significantly, a fact that makes creating a standardized input notation for generators a perennial problem.
Traditionally, workers on NLG have divided the problem into two major areas: content selection ("what shall I say?") and content expression ("how shall I say it?"). Processing in these stages is generally performed by so-called text planners and sentence realizers, respectively. More recently, two further developments have occurred: first, as generators became more expressive, the control of stylistic variation ("why should I say it this way?") has become important; second, an intermediate stage of sentence planning has been introduced to fill the "generation gap" between text planners and sentence realizers. The canonical generator architecture appears in figure 1. No generator created to date fully embodies all these modules. Pilot attempts at comprehensive architectures are ERMA (Clippinger 1974) and PAULINE (Hovy 1988). Most generators contain just some of these stages, in various arrangements; see Reiter (1994) and De Smedt, Horacek, and Zock (1995).
Figure 1 Architecture of idealized complete text generation system (without feedback between modules).
Stage 1: Text Planning Accepting one or more communicative goals from the host system, the text planner's two tasks are to select the appropriate content material to express, and to order that material into a coherently flowing sequence. A typical input goal might be [DESCRIBE HOUSE-15] or [MOTIVATE GOING-ON-VACATION-12], where the terms with numbers denote specific packages of information. After planning, the output is generally a tree structure or an ordered list of more detailed content propositions, linked together by discourse connectives signaled by "therefore," "and," "however," and so on. Usually, each proposition represents approximately the information contained in a single-clause sentence. Thus, the initial goal [DESCRIBE HOUSE-15] may be expanded into a text plan containing (in simplified notation) [GENERATE HOUSE- IDENTIFIER] [GENERATE ADDRESS] [INTRODUCE FLOORPLAN] [ELABORATE [GENERATE GROUND-FLOOR] "and" [GENERATE TOP-FLOOR] "and" [GENERATE BASEMENT]] and so on. Generally, text planning is considered to be language-independent.
The two principal methods for performing the text planning tasks involve schemas and so-called rhetorical relations. Schemas (McKeown 1985; Paris 1993; see SCHEMATA) are the simplest and most popular, useful when the texts follow a fairly stereotypical structure, such as short encyclopedia articles or business reports. Each schema specifies the typical sequence of units of content material (or of other schemata; they may be nested); for example, the order of floors. Rhetorical relations (e.g., Elaboration, Justification, Background) organize material by specifying which units of material (or blocks of units) should be selected and linked in sequence. Several collections of relations have been proposed; Rhetorical Structure Theory (Mann and Thompson 1988) and the associated method of planning (Hovy 1993; Moore 1989) are typical.
Stage 2: Sentence Planning Until the early 1990s, sentence-planning tasks were performed during text planning or sentence realization. Increasingly, however, sentence planning is seen as a distinct stage; this clarifies the generation process and makes focused investigation of subtasks easier.
Accepting from the text planner a text structure, some of the sentence planner's tasks include: specifying sentence boundaries; organizing (ordering, relativizing, etc.) the material internal to each sentence; planning cross-sentence reference and other anaphora; selecting appropriate words and phrases to express content; and specifying tense, mode (active or passive), as well as other syntactic parameters. The ideal output of a sentence planner is a list of clause-sized units containing a fairly complete syntactic specification for each clause; see Meteer (1990) for a thoughtful study.
In the example, the sentence planner must decide whether to generate each floor plan as a separate sentence or to conjoin them (and if so, to choose an appropriate conjunction). It must decide whether to say, for example, "the ground floor contains . . ." or "the ground floor has the following rooms . . . ," or any of numerous other formulations. It must decide whether to say "living room" or "sitting room"; "den" or "family room." The interrelatedness and wide range of variation of such individual aspects makes sentence planning a difficult task, as anyone who has ever written an essay knows. A considerable amount of research on individual sentence-planning tasks exists (see the readings below), but there is relatively little on their integration (see Appelt 1985; Nirenburg et al. 1988).
Stage 3: Sentence Realization Accepting from the sentence planner a list of sentence specifications, the sentence realizer's tasks are to determine the grammatically correct order of words; to inflect words for tense, number, and so on, as required by the language; and to add punctuation, capitalization, and the like. These tasks are language-dependent.
Realization is the most extensively studied stage of generation. The principal knowledge required is a grammar of syntactic rules and a lexicon of words. Different theories of SYNTAX have led to very different approaches to realization. Realization algorithms include unification (Elhadad 1992), Systemic network traversal (Mann and Matthiessen 1985), phrase expansion (Meteer et al. 1987), head-driven and reversible methods (Van Noord 1990; St. Dizier 1992), simulated annealing (De Smedt 1990), connectionist architectures (Ward 1990), and statistically based management of underspecification (Knight and Hatzivassiloglou 1995). The systems Penman (Mann and Matthiessen 1985; later extended as KPML; Bateman 1994), FUF/SURGE (Elhadad 1992), and MUMBLE (Meteer et al. 1987) have been distributed and used by several external users.
In the example, the specification (in simplified form):
as produced by the sentence planner will be interpreted by the grammar rules to form a sentence such as "the ground floor has four rooms."
Stylistic Control Throughout the generation process, some agency has to ensure the consistency of choices, whose net effect is the style of the text. Since different styles have different communicative effects, the stylistic control module must use high-level pragmatic parameters initially specified for the system (such as degree of formality, the addressee's language level, amount of time available, communication genre) to govern its overall decision policies. These policies determine the selection of the most appropriate option from the options facing any generator module at each point during the planning and realization process.
Few studies have been performed on this aspect of generation; lexicons, grammars, and sets of planning rules are still too small to necessitate much stylistic guidance. Furthermore, the complexity of interaction of choices across the stages of generation requires deep attention: how does the choice of word "freedom fighter"/"terrorist"/"guerrilla" interact with the length of the sentences near it, or with the choice of active or passive mode? See Jameson (1987), Hovy (1988), and DiMarco and Hirst (1990) for studies.
Generation Techniques Two core operations are performed throughout the generation process: content selection and ordering. For text planning, the items are units of meaning representation; for realization, the items are grammatical constituents and/or words. To do this, almost all generators use one of the following four basic techniques.
Canned items: Predefined sentences or paragraphs are selected and printed without modification. This approach is used for simple applications.
Templates: Predefined structures that allow some variation are selected, and their blank spaces filled with items specified by the content. The blanks usually have associated requirements that specify what kinds of information may fill them.
Cascaded patterns: An initial abstract pattern is selected, and each of its pieces are replaced by successively more detailed patterns, forming a tree structure with, at its leaves, the target elements. An example is traditional phrase-structure grammars, with words as target elements. The selection of suitable patterns for further expansion is guided by the content to be generated. Example realizer: MUMBLE (Meteer et al. 1987), using grammar rules as patterns; example text planner: TEXT (McKeown 1985), using schemas as patterns.
Features: In the most sophisticated approach to realization, grammar rules, lexical items, and the input notation are all encoded as collections of features, using the same type of notation. A process called unification is employed to compare the input's features against all possible grammar rules and lexical items to determine which combination of rules and items matches. For example, the specification for the sentence "the ground floor has four rooms" given above will unify with the feature-based grammar rule:
where each variable X is then associated with the appropriate portion of the input and subsequently unified against other rules. And the word "rooms" is obtained from the lexicon by successfully unifying the input's subject with the lexical item.
Example realizer: FUF/SURGE (Elhadad 1992).
Using features a different way, the influential Penman system (Mann and Matthiessen 1985) contains a network of decision points that guide the system to identify appropriate features, whose ultimate combination specifies the desired sentence structure and lexical items.
Appelt, D. E. (1985). Planning English Sentences. Cambridge: Cambridge University Press.
Bateman, J. A. (1994). KPML: The KOMET-Penman (Multilingual) Development Environment. Darmstadt, Germany: Technical Report, IPSI Institute.
Clippinger, J. H. (1974). A Discourse Speaking Program as a Preliminary Theory of Discourse Behavior and a Limited Theory of Psychoanalytic Discourse. Ph.D. diss., University of Pennsylvania.
De Smedt, K. J. M. J. (1990). Incremental Sentence Generation. Ph.D. diss., University of Nijmegen.
De Smedt, K. J. M. J., H. Horacek, and M. Zock. (1995). Architectures for natural language generation: problems and perspectives. In G. Adorni and M. Zock, Eds., Trends in Natural Language Generation: An Artificial Intelligence Perspective. Heidelberg, Germany: Springer-Verlag Lecture Notes in AI, No. 1036, pp. 17-46.
DiMarco, C., and G. Hirst. (1990). A computational theory of goal-directed style in syntax. Computational Linguistics 19(3):451-500.
Elhadad, M. (1992). Using Argumentation to Control Lexical Choice: A Functional Unification-Based Approach. Ph.D. diss., Columbia University.
Hovy, E. H. (1988). Generating Natural Language under Pragmatic Constraints. Hillsdale: Erlbaum.
Hovy, E. H. (1993). Automated discourse generation using discourse structure relations. Artificial Intelligence 63(1-2):341-386 Special Issue on Natural Language Processing.
Jameson, A. (1987). How to appear to be conforming to the "maxims" even if you prefer to violate them. In G. Kempen, Ed., Natural Language Generation: Recent Advances in Artificial Intelligence, Psychology, and Linguistics. Dordrecht: Kluwer, pp. 19-42.
Knight, K., and V. Hatzivassiloglou. (1995). Two-level, many-paths generation. In Proceedings of the 33rd Conference of the Association for Computational Linguistics, pp. 252-260.
Mann, W. C., and C. M. I. M. Matthiessen. (1985). Nigel: A systemic grammar for text generation. In R. Benson and J. Greaves, Eds., Systemic Perspectives on Discourse: Selected Papers from the Ninth International Systemics Workshop. London: Ablex, pp. 95-135.
Mann, W. C., and S. A. Thompson. (1988). Rhetorical structure theory: Toward a functional theory of text organization. Text 8:243-281. Also available as USC/Information Sciences Institute Research Report RR-87-190.
McKeown, K. R. (1985). Text Generation: Using Discourse Strategies and Focus Constraints to Generate Natural Language Text. Cambridge: Cambridge University Press.
Meteer, M. W. (1990). The Generation Gap: The Problem of Expressibility in Text Planning. Ph.D. diss., University of Massachusetts. Available as BBN Technical Report 7347.
Meteer, M., D. D. McDonald, S. Anderson, D. Foster, L. Gay, A. Huettner, and P. Sibun. (1987). Mumble-86: Design and Implementation. Amherst: University of Massachusetts Technical Report COINS-87-87.
Moore, J. D. (1989). A Reactive Approach to Explanation in Expert and Advice-Giving Systems. Ph.D. diss., University of California at Los Angeles.
Nirenburg, S., R. McCardell, E. Nyberg, S. Huffman, E. Kenschaft, and I. Nirenburg. (1988). Lexical realization in natural language generation. In Proceedings of the 2nd Conference on Theoretical and Methodological Issues in Machine Translation. Pittsburgh, pp. 18-26.
Paris, C. L. (1993). The Use of Explicit Models in Text Generation. London: Francis Pinter.
Reiter, E. B. (1994). Has a consensus NL generation architecture appeared, and is it psychologically plausible? In Proceedings of the 7th International Workshop on Natural Language Generation. Kennebunkport, pp. 163-170.
St. Dizier, P. (1992). A constraint logic programming treatment of syntactic choice in natural language generation. In R. Dale, E. H. Hovy, D. Roesner, and O. Stock, Eds., Aspects of Automated Natural Language Generation. Heidelberg, Germany: Springer-Verlag Lecture Notes in AI, No. 587, pp. 119-134.
Van Noord, G. J. M. (1990). An overview of head-driven bottom-up generation. In R. Dale, C. S. Mellish, and M. Zock, Eds., Current Research in Natural Language Generation. London: Academic Press, pp. 141-165.
Ward, N. (1990). A connectionist treatment of grammar for generation. In Proceedings of the 5th International Workshop on Language Generation. University of Pittsburgh, pp. 95-102.
Adorni, G., and M. Zock, Eds. (1996). Trends in Natural Language Generation: An Artificial Intelligence Perspective. Heidelberg, Germany: Springer-Verlag Lecture Notes in AI, No. 1036.
Bateman, J. A., and E. H. Hovy. (1992). An overview of computational text generation. In C. Butler, Ed., Computers and Texts: An Applied Perspective. Oxford: Blackwell, pp. 53-74.
Cole, R., J. Mariani, H. Uszkoreit, A. Zaenen, and V. Zue. (1996). Survey of the State of the Art of Human Language Technology. Report commissioned by NSF and LRE; http://www.cse.ogi.edu/CSLU/HLTsurvey/.
Dale, R. (1990). Generating recipes: An overview of EPICURE. In R. Dale, C. Mellish, and M. Zock, Eds., Current Research in Natural Language Generation. New York: Academic Press, pp. 229-255.
Dale, R., E. H. Hovy, D. Röesner, and O. Stock, Eds. (1992). Aspects of Automated Natural Language Generation. Heidelberg, Germany: Springer-Verlag Lecture Notes in AI, No. 587.
Goldman, N. M. (1974). Computer Generation of Natural Language from a Deep Conceptual Base. Ph.D. diss., Stanford University. Also in R. C. Schank, Ed., (1975) Conceptual Information Processing. Amsterdam: Elsevier, pp. 54-79.
Horacek, H. (1992). An integrated view of text planning. In R. Dale, E. H. Hovy, D. Röesner, and O. Stock, Eds., Aspects of Automated Natural Language Generation. Heidelberg, Germany: Springer-Verlag Lecture Notes in AI, No. 587, pp. 57-72.
Kempen, G., Ed. (1987). Natural Language Generation: Recent Advances in Artificial Intelligence, Psychology, and Linguistics. Dordrecht: Kluwer.
Lavoie, B., and O. Rambow. (1997). A fast and portable realizer for text generation systems. In Proceedings of the 5th Conference on Applied Natural Language Processing. Washington, pp. 73-79.
Paris, C. L., W. R.Swartout, and W. C. Mann, Eds. (1990). Natural Language Generation in Artificial Intelligence and Computational Linguistics. Dordrecht: Kluwer.
Reiter, E. B. (1990). Generating Appropriate Natural Language Object Descriptions. Ph.D. diss., Harvard University.
Reiter, E. B., C. Mellish, and J. Levine. (1992). Automatic generation of on-line documentation in the IDAS project. In Proceedings of the 3rd Conference on Applied Natural Language Processing. Association for Computational Linguistics, pp. 64-71.
Robin, J. (1990). Lexical Choice in Language Generation. Ph.D. diss., Columbia University, Technical Report CUCS-040-90.
![]() Copyright © 1999 Massachusetts Institute of Technology
Copyright © 1999 Massachusetts Institute of Technology