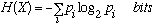
Equation 1
Information theory is a branch of mathematics that deals with measures of information and their application to the study of communication, statistics, and complexity. It originally arose out of communication theory and is sometimes used to mean the mathematical theory that underlies communication systems. Based on the pioneering work of Claude Shannon (1948), information theory establishes the limits to the shortest description of an information source and the limits to the rate at which information can be sent over a communication channel. The results of information theory are in terms of fundamental quantities like entropy, relative entropy, and mutual information, which are defined using a probabilistic model for a communication system. These quantities have also found application to a number of other areas, including statistics, computer science, complexity and economics. In this article, we will describe these basic quantities and some of their applications. Terms like information and entropy are richly evocative with multiple meanings in everyday usage; information theory captures only some of the many facets of the notion of information. Strictly speaking, information theory is a branch of mathematics, and care should be taken in applying its concepts and tools to other areas.
Information theory relies on the theory of PROBABILITY to model information sources and communication channels. A source of information produces a message out of a set of possible messages. The difficulty of communication or storage of the message depends only on length of the representation of the message and can be isolated from the meaning of the message. If there is only one possible message, then no information is transmitted by sending that message. The amount of information obtained from a message is related to its UNCERTAINTY -- if something is very likely, not much information is obtained when it occurs. The simplest case occurs when there are two equally likely messages -- the messages can then be represented by the symbols 0 and 1 and the amount of information transmitted by such a message is one bit. If there are four equally likely messages, the messages can be represented by 00, 01,10 and 11, and thus require two bits for its representation. For equally likely messages, the number of bits required grows logarithmically with the number of possibilities. When the messages are not equally likely, we can model the message source by a random variable X, which takes on values 1, 2, . . . with probabilities p1, p2, . . . , with associated entropy defined as
Equation 1
The entropy is a measure of the average uncertainty of the random variable. It can be shown (Cover and Thomas 1991) that the entropy of a random variable is a lower bound to the average length of any uniquely decodable representation of the random variable. For a uniformly distributed random variable taking on 2k possible values, the entropy of the random variable is k bits, and it is easy to see how an outcome could be represented by a k bit number. When the random variable is not uniformly distributed, it is possible to get a lower average length description by using fewer bits to describe the most frequently occurring outcomes, and more bits to describe the less frequent outcomes. For example, if a random variable takes on the values A, B, C, and D with probabilities 0.5, 0.25, 0.125, and 0.125 respectively, then we can use a code 0, 10, 110, 111 to represent these four outcomes with an average length of 1.75 bits, which is less than the two bits required for the equal length code. Note that in this example, the average codeword length is equal to the entropy. In general, the entropy is a lower bound on the average length of any uniquely decodable code, and there exists a code that achieves an average length that is within one bit of the entropy.
Traditional information theory was developed using probabilistic models, but it was extended to arbitrary strings using notions of program length by the work of Kolmogorov (1965), Chaitin (1966), and Solomonoff (1964). Suppose one has to send a billion bits of p to a person on the moon. Instead of sending the raw bits, one could instead send a program to calculate p and let the receiver reconstruct the bits. Because the length of the program would be much shorter than the raw bits, we compress the string using this approach. This motivates the following definition forKolmogorov complexity or algorithmic complexity: The Kolmogorov complexity Ku(x) is the length of the shortest program for a universal TURING machine U (see AUTOMATA) that prints out the string x and halts. Using the fact that any universal Turing machine can simulate any other universal Turing machine using a fixed length simulation program, it is easy to see that the Kolmogorov complexity with respect to two different Turing machines differs by at most a constant (the length of the simulation program). Thus the notion of Kolmogorov complexity is universal up to a constant. For random strings, it can be shown that with high probability, the Kolmogorov complexity is equivalent to the entropy rate of the random process. However, due to the halting problem, it is not always possible to discover the shortest program for a string, and thus it is not always possible to determine the Kolmogorov complexity of a string. But Kolmogorov or algorithmic complexity provides a natural way to think about complexity and data compression and has been developed into a rich and deep theory (Li and Vitanyi 1992) with many applications (see MINIMUM DESCRIPTION LENGTH and COMPUTATIONAL COMPLEXITY).
Transmission of information over a communication channel is subject to noise and interference from other senders. A fundamental concept of information theory is the notion of channel capacity, which plays a role very similar to the capacity of a pipe carrying water -- information is like an incompressible fluid that can be sent reliably at any rate below capacity. It is not possible to send information reliably at a rate above capacity. A communication channel is described by a probability transition function p(y|x), which models the probability of a particular output message y when input signal x is sent. The capacity C of the channel can then be calculated as
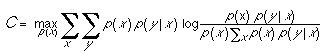
Equation 2
A key result of information theory is that if the entropy rate of a source is less than the capacity of a channel, then the source can be reproduced at the output of the channel with negligible error, whereas if the entropy rate is greater than the capacity, the error cannot be made arbitrarily small. This result, due to Shannon (1948), created a sensation when it first appeared. Before Shannon, communication engineers believed that the only way to increase reliability in the presence of noise was to reduce the rate by repeating messages, and that to get arbitrarily high reliability one would need to send at a vanishingly small rate. Shannon proved that this was not necessary; at any rate below the capacity of the channel, it is possible to send information with arbitrary reliability by appropriate coding and decoding. The methods used by Shannon were not explicit, but subsequent research has developed practical codes that allow communication at rates close to capacity. These codes are used in combating errors and noise in most current digital systems, for example, in CD players and modems.
Another fundamental quantity used in information theory and in statistics is the relative entropy or Kullback-Leibler distance D(p || q) between probability mass functions p and q, which is defined as
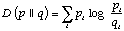
Equation 3
The relative entropy is a measure of the difference between two distributions. It is always nonnegative, and is zero if and only if the two distributions are the same. However, it is not a true distance measure, because it is not symmetric. The relative entropy plays a key role in large deviation theory, where it is the exponent in the probability that data drawn according to one distribution looks like data from the other distribution. Thus if a experimenter observes n samples of data and wants to decide if the data that he has observed is drawn from the distribution p or the distribution q, then the probability that he will think that the distribution is p when the data is actually drawn from q is approximately 2-nD(p || q).
We have defined entropy and relative entropy for single discrete random variables. The definitions can be extended to continuous random variables and random processes as well. Because a real number cannot be represented fully with a finite number of bits, a branch of information theory called rate distortion theory characterizes the tradeoff between the accuracy of the representation (the distortion) and the length of the description (the rate). The theory of communication has also been extended to networks with multiple senders and receivers and to information recording (which can be considered as information transmission over time as opposed to information transmission over space).
Information theory has had a profound impact on the technology of the information age. The fact that most information now is stored and transmitted in digital form can be considered a result of one of the fundamental insights of the theory, that the problem of data compression can be separated from the problem of optimal transmission over a communication channel without any loss in achievable performance. Over the half century since Shannon's original work, complex source coding and channel coding schemes have been developed that have come close to fulfilling the bounds that are derived in the theory. These fundamental bounds on description length and communication rates apply to all communication systems, including complex ones like the nervous system or the brain (Arbib 1995). The quantities defined by information theory have also found application in many other fields, including statistics, computer science, and economics.
Arbib, M. A. (1995). The Handbook of Brain Theory and Neural Networks. Cambridge, MA: Bradford Books/MIT Press.
Chaitin, G. J. (1966). On the length of programs for computing binary sequences. J. Assoc. Comp. Mach. 13:547-569.
Cover, T. M., and J. A. Thomas. (1991). Elements of Information Theory. New York: Wiley.
Kolmogorov, A. N. (1965). Three approaches to the quantitative definition of information. Problems of Information Transmission 1:4-7.
Li, M., and P. Vitanyi. (1992). Introduction to Kolmogorov Complexity and its Applications. New York: Springer.
Shannon, C. E. (1948). A mathematical theory of communication. Bell Sys. Tech. Journal 27:379-423, 623 - 656.
Solomonoff, R. J. (1964). A formal theory of inductive inference. Information and Control 7:1-22, 224 - 254 .
![]() Copyright © 1999 Massachusetts Institute of Technology
Copyright © 1999 Massachusetts Institute of Technology