One of the major problems which must be solved by a visual system used for object recognition is the building of a representation of visual information which allows recognition to occur relatively independently of size, contrast, spatial frequency, position on the RETINA, and angle of view, etc. It is important that invariance in the visual system is made explicit in the neuronal responses, for this simplifies greatly the output of the visual system to memory systems such as the HIPPOCAMPUS and AMYGDALA, which can then remember or form associations about objects (Rolls 1999). The function of these memory systems would be almost impossible if there were no consistent output from the visual system about objects (including faces), for then the memory systems would need to learn about all possible sizes, positions, etc. of each object, and there would be no easy generalization from one size or position of an object to that object when seen with another retinal size, position, or view (see Rolls and Treves 1998).
The primate inferior temporal visual cortex is implicated by lesion evidence in providing invariance. For example, Weiskrantz and Saunders (1984; see also Weiskrantz 1990) showed that macaques with inferior temporal cortex lesions performed especially poorly in visual discrimination tasks when one of the objects was shown in a different size or in different lighting.
Using the population of neurons in the cortex in the superior temporal sulcus and inferior temporal cortex with responses selective for faces, it has been found that the responses are relatively invariant with respect to size and contrast (Rolls and Baylis 1986); spatial frequency (Rolls, Baylis, and Leonard, 1985; Rolls, Baylis, and Hasselmo, 1987) and retinal translation, that is, position in the visual field (Tovee, Rolls, and Azzopardi 1994; cf. earlier work by Gross 1973; Gross et al. 1985). Some of these neurons even have relatively view-invariant responses, responding to different views of the same face but not of other faces (Hasselmo et al. 1989; see FACE RECOGNITION).
To investigate whether view-invariant representations of objects are also encoded by some neurons in the inferior temporal cortex (area TE) of the rhesus macaque, the activity of single neurons was recorded while monkeys were shown very different views of ten objects (Booth and Rolls 1998). The stimuli were presented for 0.5 sec on a color video monitor while the monkey performed a visual fixation task. The stimuli were images of ten real plastic objects which had been in the monkey's cage for several weeks to enable him to build view-invariant representations of the objects. Control stimuli were views of objects which had never been seen as real objects. The neurons analyzed were in the TE cortex in and close to the ventral lip of the anterior part of the superior temporal sulcus. Many neurons were found that responded to some views of some objects. However, for a smaller number of neurons, the responses occurred only to a subset of the objects, irrespective of the viewing angle. These latter neurons thus conveyed information about which object had been seen, independently of view, as confirmed by information-theoretic analysis of the neuronal responses.
The representation of objects or faces provided by these neurons is distributed, in that each NEURON does not, in general, respond to only one object or face, but instead responds to a subset of the faces or objects. They thus showed ensemble, sparsely distributed, encoding (Rolls and Tovee 1995; Rolls et al. 1997). One advantage of this encoding is that it allows receiving neurons to generalize to somewhat similar exemplars of the stimuli, because effectively it is the activity of the population vector of neuronal firing which can be read out by receiving neurons (Rolls and Treves 1998). A second advantage is that the information available from such a population about which face or object was seen increases approximately linearly with the number of neurons in the sample (Abbott, Rolls, and Tovee 1996; Rolls et al. 1997). This means that the number of stimuli that can be represented increases exponentially with the number of cells in the sample (because information is a logarithmic measure). This has major implications for brain operation, for it means that a receiving neuron or neurons can receive a great deal of information from a sending population if each receiving neuron receives only a limited number of afferents (100-1000) from a sending population.
A way in which artificial vision systems might encode information about objects is to store the relative coordinates in 3-D object-based space of parts of objects in a database, and to use general-purpose algorithms on the inputs to perform transforms such as translation, rotation, and scale change in 3-D space to see if there is any match to a stored 3-D representation (e.g., Marr 1982). One problem (see also Rolls and Treves 1998) with implementing such a scheme in the brain is that a detailed syntactical description of the relations between the parts of the 3-D object is required, for example, body > thigh > shin > foot > toes. Such syntactical networks are difficult to implement in neuronal networks, because if the representations of all the features just mentioned were active simultaneously, how would the spatial relations between the features also be encoded? (How would it be apparent just from the firing of neurons that the toes were linked to the rest of foot but not to the body?) Another more recent suggestion for a syntactically linked set of descriptors is that of Biederman (1987; see also Hummel and Biederman 1992).
An alternative, more biologically plausible scheme is that the brain might store a few associated 2-D views of objects, with generalization within each 2-D view, in order to perform invariant object and face recognition (Koenderink and Van Doorn 1979; Poggio and Edelman 1990; Rolls 1992, 1994; Logothetis et al. 1994; Wallis and Rolls 1997). The way in which the brain could learn and access such representations is described next.
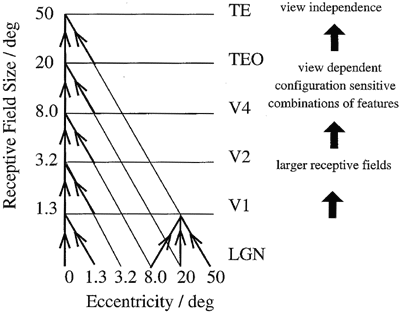
Cortical visual processing for object recognition is considered to be organized as a set of hierarchically connected cortical regions consisting at least of V1, V2, V4, posterior inferior temporal cortex (TEO), inferior temporal cortex (e.g., TE3, TEa, and TEm), and anterior temporal cortical areas (e.g., TE2 and TE1). There is convergence from each small part of a region to the succeeding region (or layer in the hierarchy) in such a way that the receptive field sizes of neurons (e.g., one degree near the fovea in V1) become larger by a factor of approximately 2.5 with each succeeding stage (and the typical parafoveal receptive field sizes found would not be inconsistent with the calculated approximations of, for example, eight degrees in V4, twenty degrees in TEO, and fifty degrees in inferior temporal cortex; Boussaoud, Desimone, and Ungerleider 1991; see figure 1). Such zones of convergence would overlap continuously with each other. This connectivity would be part of the architecture by which translation-invariant representations are computed. Each layer is considered to act partly as a set of local self-organizing competitive neuronal networks with overlapping inputs. These competitive nets (described, e.g, by Rolls and Treves 1998) operate to detect correlations between the activity of the input neurons, and to allocate output neurons to respond to each cluster of such correlated inputs. These networks thus act as categorizers, and help to build feature analyzers. In relation to visual information processing, they would remove redundancy from the input representation.
Translation invariance would be computed in such a system by utilizing competitive learning to detect statistical regularities in inputs when real objects are translated in the physical world. The hypothesis is that because objects have continuous properties in space and time in the world, an object at one place on the retina might activate feature analyzers at the next stage of cortical processing, and when the object was translated to a nearby position, because this would occur in a short period (e.g., 0.5 sec), the membrane of the postsynaptic neuron would still be in its "Hebb-modifiable" state (caused for example by calcium entry as a result of the voltage-dependent activation of N-methyl-d-aspartate receptors), and the presynaptic afferents activated with the object in its new position would thus become strengthened on the still-activated postsynaptic neuron. It is proposed that the short temporal window (e.g., 0.5 sec) of Hebb modifiability helps neurons to learn the statistics of objects moving in the physical world, and at the same time to form different representations of different feature combinations or objects, as these are physically discontinuous and present less regular statistical correlations to the visual system. Foldiak (1991) has proposed computing an average activation of the postsynaptic neuron to assist with the same problem. The idea here is that the temporal properties of the biologically implemented learning mechanism are such that it is well suited to detecting the relevant continuities in the world of real objects. Rolls (1992, 1994) has also suggested that other invariances, for example, size, spatial frequency, and rotation invariance, could be learned by a comparable process. (Early processing in V1, which enables different neurons to represent inputs at different spatial scales, would allow combinations of the outputs of such neurons to be formed at later stages. Scale invariance would then result from detecting at a later stage which neurons are almost conjunctively active as the size of an object alters.) It is proposed that this process takes place at each stage of the multiple-layer cortical-processing hierarchy, so that invariances are learned first over small regions of space, and then over successively larger regions. This limits the size of the connection space within which correlations must be sought.
View-independent representations could be formed by the same type of computation, operating to combine a limited set of views of objects. Consistent with the suggestion that the view-independent representations are formed by combining view-dependent representations in the primate visual system is the fact that in the temporal cortical areas, neurons with view-independent representations of faces are present in the same cortical areas as neurons with view-dependent representations (from which the view-independent neurons could receive inputs; Hasselmo et al. 1989; Perrett, Mistlin, and Chitty 1987).
This hypothesis about the computation of invariant representations has been implemented in a computational model by Wallis and Rolls (1997), and a related model with a trace version of the Hebb rule implemented in recurrent collateral connections has been analyzed using the methods of statistical physics (Parga and Rolls 1998).
Another suggestion for the computation of translation invariance is that the image of an object is translated to standard coordinates using a circuit in V1 that has connections for every possible translation, and switching on in a multiplication operation just the correct set of connections (Olshausen, Anderson, and Van Essen 1993). This scheme does not appear to be fully plausible biologically, in that all possible sets of connections do not appear to be present (in the brain), the required multiplier inputs and multiplication synapses do not appear to be present; and such a scheme could perform translation-invariant mapping in one stage, whereas in the brain it takes place gradually over the whole series of visual cortical areas V1, V2, V4, posterior inferior temporal, and anterior inferior temporal, with an expansion of the receptive field size (and thus of translation invariance) of approximately 2.5 at each stage (see figure 1 and Rolls 1992, 1994; Wallis and Rolls 1997; Rolls and Treves 1998).
Figure 1 Schematic diagram showing convergence achieved by the forward projections in the visual system, and the types of representation that may be built by competitive networks operating at each stage of the system, from the primary visual cortex (V1) to the inferior temporal visual cortex (area TE; see text). LGN -- lateral geniculate nucleus. Area TEO forms the posterior inferior temporal cortex. The receptive fields in the inferior temporal visual cortex (e.g., in the TE areas) cross the vertical midline (not shown).
Abbott, L. A., E. T. Rolls, and M. J. Tovee. (1996). Representational capacity of face coding in monkeys. Cerebral Cortex 6:498-505.
Biederman, I. (1987). Recognition-by-components: A theory of human image understanding. Psychological Review 94:115-147.
Booth, M. C. A., and E. T. Rolls. (1998). View-invariant representations of familiar objects by neurons in the inferior temporal visual cortex. Cerebral Cortex 8:510-523.
Boussaoud, D., R. Desimone, and L. G. Ungerleider. (1991). Visual topography of area TEO in the macaque. Journal of Comparative Neurology 306:554-575.
Foldiak, P. (1991). Learning invariance from transformation sequences. Neural Computation 3:193-199.
Gross, C. G. (1973). Inferotemporal cortex and vision. Progress in Psychobiology and Physiological Psychology. 5:77-123.
Gross, C. G., R. Desimone, T. D. Albright, and E. L. Schwartz. (1985). Inferior temporal cortex and pattern recognition. Experimental Brain Research 11 (Suppl.) 179-201.
Hasselmo, M. E., E. T. Rolls, G. C. Baylis, and V. Nalwa. (1989). Object-centered encoding by face-selective neurons in the cortex in the superior temporal sulcus of the monkey. Experimental Brain Research 75:417-429.
Hummel, J. E., and I. Biederman. (1992). Dynamic binding in a neural network for shape recognition. Psychological Review 99:480-517.
Koenderink, J. J., and A. J. Van Doorn. (1979). The internal representation of solid shape with respect to vision. Biological Cybernetics 32:211-216.
Logothetis, N. K., J. Pauls, H. H. Bülthoff, and T. Poggio. (1994). View-dependent object recognition by monkeys. Current Biology 4:401-414.
Marr, D. (1982). Vision. San Francisco: W. H. Freeman.
Olshausen, B. A., C. H. Anderson, and D. C. Van Essen. (1993). A neurobiological model of visual attention and invariant pattern recognition based on dynamic routing of information. Journal of Neuroscience 13:4700-4719.
Parga, N., and E. T. Rolls. (1998). Transform invariant recognition by association in a recurrent network. Neural Computation 10:1507-1525.
Perrett, D. I., A. J. Mistlin, and A. J. Chitty. (1987). Visual neurons responsive to faces. Trends in Neuroscience 10:358-364.
Poggio, T., and S. Edelman. (1990). A network that learns to recognize three-dimensional objects. Nature 343:263-266.
Rolls, E. T. (1992). Neurophysiological mechanisms underlying face processing within and beyond the temporal cortical visual areas. Philosophical Transactions of the Royal Society of London, Series B: Biological Sciences 335:11-21.
Rolls, E. T. (1994). Brain mechanisms for invariant visual recognition and learning. Behavioural Processes 33:113-138.
Rolls, E. T. (1995). Learning mechanisms in the temporal lobe visual cortex. Behavioural Brain Research 66:177-185.
Rolls, E. T. (1999). The Brain and Emotion. Oxford: Oxford University Press.
Rolls, E. T., and G. C. Baylis. (1986). Size and contrast have only small effects on the responses to faces of neurons in the cortex of the superior temporal sulcus of the monkey. Experimental Brain Research 65:38-48.
Rolls, E. T., G. C. Baylis, and M. E. Hasselmo. (1987). The responses of neurons in the cortex in the superior temporal sulcus of the monkey to band-pass spatial frequency filtered faces. Vision Research 27:311-326.
Rolls, E. T., G. C. Baylis, and C. M. Leonard. (1985). Role of low and high spatial frequencies in the face-selective responses of neurons in the cortex in the superior temporal sulcus. Vision Research 25:1021-1035.
Rolls, E. T., and M. J. Tovee. (1995). Sparseness of the neuronal representation of stimuli in the primate temporal visual cortex. Journal of Neurophysiology 73:713-726.
Rolls, E. T., and A. Treves. (1998). Neural Networks and Brain Function. Oxford: Oxford University Press.
Rolls, E. T., A. Treves, M. Tovee, and S. Panzeri. (1997). Information in the neuronal representation of individual stimuli in the primate temporal visual cortex. Journal of Computational Neuroscience 4:309-333.
Tovee, M. J., E. T. Rolls, and P. Azzopardi. (1994). Translation invariance and the responses of neurons in the temporal visual cortical areas of primates. Journal of Neurophysiology 72:1049-1060.
Wallis, G., and E. T. Rolls. (1997). Invariant face and object recognition in the visual system. Progress in Neurobiology 51:167-194.
Weiskrantz, L. (1990). Visual prototypes, memory and the inferotemporal cortex. In E. Iwai and M. Mishkin, Eds., Vision, Memory and the Temporal Lobe. New York: Elsevier, pp. 13-28.
Weiskrantz, L., and R. C. Saunders. (1984). Impairments of visual object transforms in monkeys. Brain 107:1033-1072.
Ullman, S. (1996). High-Level Vision: Object Recognition and Visual Cognition. Cambridge, MA: MIT Press/Bradford Books.
![]() Copyright © 1999 Massachusetts Institute of Technology
Copyright © 1999 Massachusetts Institute of Technology